해시테이블은 특정 키(key)에 값(value)을 매칭(matching)해 저장해 놓는 자료구조로 키값에 매칭된 값을 검색 할 때 매우 빠른 속도 O(c) 를 보장한다.
실무에서도 매우 자주 사용되는 자료구조로 해시맵(hashmap) 또는 연관배열 (associative array) , 맵(map), 딕션너리(dictionary) 등으로 불리기도 한다.

해시테이블 자료구조에서 매우 중요한 핵심은 해시함수(hash function)이다.
해시테이블에서는 자료를 배열(해시테이블에서는 이 배열을 보통 버킷(bucket) or 슬롯(slot)이라 부른다.) 에 저장하는데 키가 버킷(배열)의 몇 번째 index에 해당하는지 확인하기위해 해시함수를 사용하기 때문이다.
구현을 통해서 자세히 알아보자.
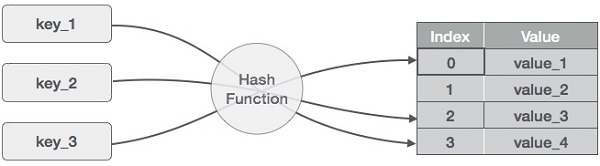
키값이 integer 이고 키에 매칭되는 값이 integer 인 아래 예제를 생각해보자.
{ (1 -> 20), (2 -> 70), (42 -> 80), (4 -> 25), (12 -> 44) , (14 -> 32) (17 -> 11), (13 -> 78), (37 - > 98) }
1키값에는 20이 저장되어 있어야 하고 2에는 70이 저장되어 있어야 한다.
우선 값들이 저장될 공간(배열 or bucket or slot) 을 먼저 정의 한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public class HashTable<K,V> {
/**
* The hash table data.
*/
private static class Bucket<K,V> {
public int hash; // 해시값
public K key; // 키
public V value; // 값
}
}
Colored by Color Scripter
|
해시테이블클래스에는 값들이 저장될 공간(배열 or bucket or slot)을 위한 [] table 이 선언되어 있고, 이어서 Bucket 클래스에는 키(ket)와 값(value)그리고 키를 해시한 값(hash)을 가지고 있다.
next 는 해시충돌(hash collision)을 위해 필요한 것인데 이 후에 설명하겠다.
이제 키에 맞는 값을 추가 (put)하는 메소드를 구현해야 하는데 전에 키에 해당 하는 것이 버킷( []table )의 어느 인덱스(index)에 저장되어야 하는지 판단하기 위해 해시함수(hash function)를 만들어야한다. 해시함수에 의해 리턴된 것이 버킷의 index 이기 때문이다.
해시함수는 매우 다양한 방법이 있는데 문제는 해시함수가 서로 다른 두 개의 키에 대해 동일한 해시값을 리턴(해시충돌 = hash collision)하지 않도록 해시값을 고르게 만들어내는 해시함수(uniform hash function)가 필요하다.
여기서는 매우 단순하게 모듈러(modular)연산자를 해시함수로 만들어서 사용하겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
public class HashTable<K,V> {
/**
* The hash table data.
*/
private static class Bucket<K,V> {
public int hash; // 해시값
public K key; // 키
public V value; // 값
}
public HashTable() {
// 처음 10개정도의 bucket table 을 생성한다.
}
public V put(K key, V value) {
int hash = key.hashCode();
// modular 연산을 통해 해시값을 얻어온다.
int index = (hash) % table.length;
// 이미 해당 버킷에 값이 있으면 새로운 값으로 업데이트하고 이전값을 리턴
Bucket<K,V> bucket = (Bucket<K,V>)table[index];
if(bucket != null) {
V old = bucket.value;
bucket.value = value
}
// 해당 버킷에 값이 없으면 추가.
bucket = new Bucket();
bucket.hash = hash;
bucket.key = key;
bucket.value = value;
table[index] = bucket;// 해싱된 index 에 bucket을 추가.
return null;
}
}
Colored by Color Scripter
|
put() 메소드는 이해하기 쉬운데 우선 객체의 hashCode()값 (숫자임) 을 얻고 모듈러 연산으로 해싱을하여 얻은 index에
이미 추가된 bucket 이 있으면 그 bucket 에 대한 값을 리턴하고 그렇치 않으면 bucket 을 새로 생성하여 해싱하여 얻은 index에 bucket을 추가해주면 끝이다.
문제는 어던 함수라도 해시함수의 충돌이 발생할수밖에 없는데 예를들어 위의 모듈러 연산을 통해 아래 데이터들을 넣게 되면
{ (1 -> 20), (2 -> 70), (42 -> 80), (4 -> 25), (12 -> 44) , (14 -> 32) (17 -> 11), (13 -> 78), (37 - > 98) }
| key | hash(key) | 버킷인덱스 |
| 1 | 1 % 20 = 1 | 1 |
| 2 | 2 % 20 = 2 | 2 |
| 42 | 42 % 20 = 2 | 2 |
| 4 | 4 % 20 = 4 | 4 |
| 12 | 12 % 20 = 12 | 12 |
| 14 | 14 % 20 = 14 | 14 |
| 17 | 17 % 20 = 17 | 17 |
| 13 | 13 % 20 = 13 | 13 |
| 37 | 37 % 20 = 17 | 17 |
2, 42 키는 해시함수에 의해 리턴된 값이 동일하므로 42키에 대한 값을 해시테이블에 추가할 수 없게 된다.
이런걸 보통 해시충돌(hash collision)이라고하는데 아무리 해시함수를 잘 만들더라도 충돌은 피할수 없기 때문에 우회할 방법이 필요하다.
해시충돌 문제를 해결하기 위해 다양한 기법들이 고안되었는데 가장 대표적인것이 chaining 과 open addressing 이다.
chaining은 해시테이블의 버킷을 관리하기위해 다른 자료구조(ex 링크드리스트)를 더 추가하여 유연하게 만드는 구조이고, open addressing은 해시테이블 버킷 크기는 고정시키되 저장해 둘 위치를 잘 찾는 데 관심을 둔 구조라고 보면 된다.
이 중 더 자주 사용되는 기법은 chaining 인데 체이닝은 해시값이 동일한 키에 대해서 동일한 버킷에 링크드리스트 형태로 추가하여 저장하는 기법이다.

위 그림을 보면 18과 10키에 대해 modular hash funciton 적용시 버킷 index 는 둘다 2이다.
이경우 먼저 추가된 순서대로 단일연겨리스트로 데이터를 추가해주고 있다.
물론 이렇게 하면 에 검색이나 추가시 O(c) 의 성능을 보장할수없고 worst case 인경우 O(n) 가 될수도 있다.
open addressing 는 chaining과 달리 버킷당 들어갈 수 있는 데이터가 하나뿐인데 만약 키값이 동일하면 다른 버킷 주소(index)로 재배치(probing)하여 저장하는 기법인데 특정 해시값에 키가 몰리게 되면 open addressing의 효율성은 크게 떨어질수 있다.
키값 충돌시 어느 버킷에 재배치 할지 결정하는 기법을 probing 이라고 하고 다양한 방법이 있지만 여기서는 가장 이해하기 쉬운 linear probing 에 대해서 설명한다.
linear probing 은 해싱된 버킷에 이미 데이터가 저장되어 있다면 바로 다음 index 가 비어(empty)있는지 확인합니다.
만약 비어있다면 그 index에 값을 저장하고 그렇치 않다면 다시 다음(NEXT) index 로 이동하면서 비어있는곳을 찾을때까지 계속 선형적으로 하나씩 증가하면서 찾는 방식입니다.
| 키(key) | hash(key) | 버킷인덱스 | After Linear Probing |
| 1 | 1 % 20 = 1 | 1 | 1 |
| 2 | 2 % 20 = 2 | 2 (충돌) | 2 |
| 42 | 42 % 20 = 2 | 2 (충돌) | 3 |
| 4 | 4 % 20 = 4 | 4 | 4 |
| 12 | 12 % 20 = 12 | 12 | 12 |
| 14 | 14 % 20 = 14 | 14 | 14 |
| 17 | 17 % 20 = 17 | 17 | 17 |
| 13 | 13 % 20 = 13 | 13 | 13 |
| 37 | 37 % 20 = 17 | 17 | 18 |
위 표를 보면 2, 42가 해시충돌로 인해 버킷인덱스가 2에 배치되어야 하는 상황이 발생하였다.
하지만 42는 linear probing에 의해 2 다음인 3번 인덱스가 비어져 있는지 확인하고 3번에 재배치하게 된다.
이 글에서는 chaing 방법으로 충돌을 해결하도록 구현하고 get() 메소드까지 구현하고 마무리 하도록한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
public class HashTable<K,V> {
private static class Bucket<K, V> {
public int hash; // 해시값
public K key; // 키
public V value; // 값
public Bucket(int hash, K key, V value, Bucket<K, V> e) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = e;
}
}
public HashTable() {
// 처음 10개정도의 bucket table 을 생성한다.
}
public V put(K key, V value) {
int hash = key.hashCode();
// modular 연산을 통해 해시값을 얻어온다.
int index = (hash) % table.length;
// hash 깂이 동일한 것이 이미 추가되어 값만 업데이트하고 이전 값을 리턴한다.
Bucket<K, V> entry = (Bucket<K, V>) table[index];
V old = entry.value;
entry.value = value;
return old;
}
}
// hash값이 동일한 것이 없으면 버킷의 리스트 맨앞에 데이터를 추가한다.
Bucket newEntry = new Bucket(hash, key, value, (Bucket<K, V>) table[index]);
table[index] = newEntry;
return null;
}
public V get(K key) {
int hash = key.hashCode();
// modular 연산을 통해 해시값을 얻어온다.
int index = (hash) % table.length;
// hash값이 동일한 것이 있으면 리턴.
Bucket<K, V> entry = (Bucket<K, V>) table[index];
return entry.value;
}
}
return null;
}
}
Colored by Color Scripter
|
위 코드에서 44,45 라인이 키값 충돌을 회피하기 위한 chaning 기법을 사용한 곳이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
public class Main {
public static void main(String[] args) throws IOException {
// { (1 -> 20), (2 -> 70), (42 -> 80), (4 -> 25),
// (12 -> 44) , (14 -> 32) (17 -> 11), (13 -> 78), (37 - > 98) }
HashTable<Integer, Integer> hashTable = new HashTable<>();
}
}
Colored by Color Scripter
|
자바에서는 해시테이블 자료구조를 구현한 HashTable<K,V> 또는 HashMap<K,V>, C++에서는 stl::hash_map을 제공한다.
HashTable vs HashMap 의 차이점은 thread-safe 여부인데 HashTable은 thread-safe 하고 HahsMap thread-safe 하지 않다는 차이점이 있다.
'자료구조(Data Structure)' 카테고리의 다른 글
| 배열(Array) (0) | 2019.06.18 |
|---|---|
| 링크드리스트(LinkedList) (0) | 2019.06.18 |
| 셋(Set) (0) | 2019.06.18 |
| 덱(Deque) (0) | 2019.06.18 |
| 이진탐색트리(Binary Search Tree) (0) | 2019.06.18 |



