배열(Array)에서 설명한것 처럼 뱌열은 랜덤엑세스 속도( O(c)) 에 유리하지만 중간에 삽입하거나 삭제하는경우 또는 맨 뒤에 추가할때 저장 할 사이즈가 부족하면 메모리를 재 할당하고 (메모리 할당과 해제는 cost 가 있음) 배열의 인덱스를 다시 얼라인(or reposition)해야 하는 오퍼레이션(operation)들이 필요하다.
그럼 중간이던 끝이던 앞이던 삭제하고 추가하는데 유리한 자료구조는 없을까 ?
링크드리스트(LinkedList)는 배열의 장점을 포기하고 단점을 보완할수 있는 자료구조를 가지고 있다.
링크드리스트의 종류는 여러가지가 있는데 그 중 가장 심플한 단일 링크드리스트부터 설명하겠다.
- 단일 연결 리스트(Single LinkedList)
- 더블 연결 리스트(Doubly LinkedList)
- 원형 연결 리스트(Circular LinkedList)
일단 단일 링크드리스트는 데이터를 가지고 있는 노드(NODE) 에 다음(NEXT) 노드를 가리키고(연결하고) 있는 구조로 되어 있다.
각각의 노드는 배열과 다르게 메모리가 연속된 공간에 있지 않고 랜덤하게 할당되어 있다.

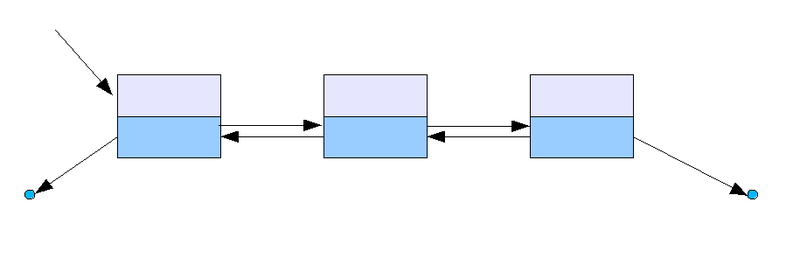
이중 연결 리스트의 구조는 단일 연결 리스트와 비슷하지만, 데이터를 가지고 있는 노드에 다음(NEXT or 앞)와 이전(PREVIOUS or 뒤) 노드를 가리키고(연결하고있는) 있는 구조로 되어 있다.
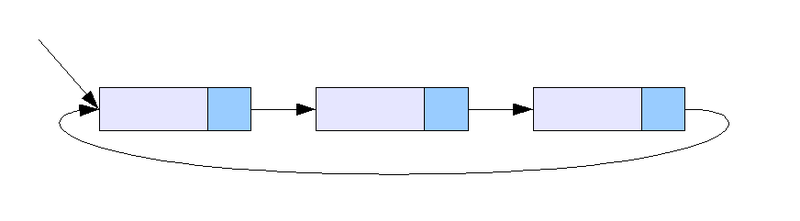
원형 연결 리스트는 일반적인 연결 리스트(single 이던 doubly 던)에 마지막(LAST) 노드와 처음(FIRST) 노드를 연결시켜 원형으로 만든 구조이다.
사실 링크드리스트는 구현을 통해 이해하는것이 쉽다.
Doubly LinkedList를 구현하면 나머지는 쉽게 유추 가능하기 때문에 여기서는 이중 연결리스트를 구현하는것만 살펴본다.
구현전에 링크드리스트가 어찌 동작하는지 https://visualgo.net/ko/list 로 가서 시뮬레이션 해본다음에 코드를 보는것이 더 이해가 잘 될것이다.
우선 LinkedList 라는 클래스(class)와 노드(Node)를 나타내는 generic 클래스를 생성하자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public class LinkedList<E> {
long size; // 노드의 총 개수.
Node<E> first; // 링크드리스트의 첫 번째 노드,를 가리킨다.
Node<E> last; // 링크드리스트의 마지막 노드를 가리킨다.
private static class Node<E> {
E item; // 노드의 아이템 값.
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
Colored by Color Scripter
|
이제 이 클래스를 바탕으로 몇 가지 함수들을 구현해 나갈 것이다.
- 추가(add)
- 삽입(insert)
- 삭제(remove)
- 엑세스
추가는 매우 심플하다.
추가될 노드의 이전 노드는 현재 링크드리스트의 마지막(last)노드로 해 주고 last 노드의 next에 생성한 노드를 가리키도록한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
public void add(E e) {
// 노드의 이전은 현재 링크드리스트의 last로 다음은 맨 마지막으로 추가될 것이니까 null 로 설정하여 추가할 노드 생성
// last (last)◁(prev) (생성한노드) (last) ▷ null
last = newNode;
if (l == null)
first = newNode; // last 노드가 null 이라면 아직 한개도 추가된 게 아니니까 first 에 저장
else
l.next = newNode; // last 의 다음(next) 노드에 생성한 노드를 가리키도록 한다.
size++;
}
Colored by Color Scripter
|
삽입은 추가하려 인덱스의 Node를 찾아 그 노드 앞(before)에 추가해준다.
Node1 (index = 0 ) <-> Node2 (index = 1) <-> Node3 (index = 2) 으로 되어 있을때 index = 1에 Node4를 삽입한다면
이때 추가해 줄 Node4의 NEXT는 Node4.next = Node2.prev가 되고 이전은 Node4.prev = Node2.prev 가리키게 하면된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public void add(int index, E e) {
Node<E> succ = findByIndex(index);
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
}
Node<E> findByIndex(int index) {
// 찾는 인덱스가 총 노드 개수의 절반 이하면 앞에서부터 슨회하여 찾는다.
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 찾는 인덱스가 총 노드 개수의 절반 이상이면 뒤 에서부터 순회하여 찾는다.
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
Colored by Color Scripter
|
find 메소드에서 index 의 위치가 전체 노드 개수의 절반을 기준으로 앞에서부터 찾을지 뒤에서 부터 찾을지 분기하는데 단일연결리스트에서는 불가능한 것이다. 왜야하면 단일 연결리스트는 NEXT 노드만 알고 PREV는 알지 못하기 때문이다.
이중연결리스트가 NEXT, PREV모두 가지고 있어야 해서 메모리가 추가로 요구되지만 배열의 장점인 랜덤 엑세스가 불가능하기 때문에 탐색을 이렇게라도 최적화 하는것이 좋다.
만약 Node1 (index = 0 ) <-> Node2 (index = 1) <-> Node3 (index = 2) Node2가 제거 한다고 하면
Node1.next = Node2.next 를 가리키게 하고 Node3.prev = Node2.prev 를 가리키게 하면 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
public E remove(int index) {
Node<E> x = findByIndex(index);
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
return element;
}
Colored by Color Scripter
|
이 처럼 링크드 리스트는 자료를 노드로 연결해서 관리하기 때문에 메모리가 연속적이지 않아 특정 index에 엑세스 하려면 앞에서 또는 뒤에서부터 순회를 해야 한다. 하지만 삽입이나 추가, 삭제등에 대한 연산은 노드(pointer)로 관리되기 때문에 배열처럼 오퍼레이션 수행후 추가적인 배열 재 얼라인이라던지 메모리 재할당 필요없이 O(c) 로 가능하다.
하지만 추가할 곳을 찾기 위해 선형검색(Linear Search)을 하기 때문에 O(c) + O(0.5N) (if Double LinkeList ) 속도가 걸린다.
만약 단일링크드 리스트인경우는 뒤에서부터 선형검색할수 없고 앞에서부터 해야하므로 당연히 O(c) + O(N) 이 걸린다.
하지만 배열에 메모리나 속도면에서 cost는 훨씬 덜 들 수 밖에 없다.
마지막으로 모든 자료구조에는 순회(traversal)이 필수이니 LinkedList를 위한 iteration 을 만들고 마친다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
public Iterator<E> listIterator(int index) {
return new ListItr();
}
private class ListItr implements Iterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
ListItr() {
next = first;
nextIndex = 0;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
}
Colored by Color Scripter
|
완성된 코드이다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
|
public class LinkedList<E> {
int size;
Node<E> first; // 링크드리스트의 첫 번째 노ㄷ,를 가리킨다.
Node<E> last; // 링크드리스트의 마지막 노드를 가리킨다.
private static class Node<E> {
E item; // 노드의 아이템 값.
this.item = element;
this.next = next;
this.prev = prev;
}
}
public void add(E e) {
// 노드의 이전은 현재 링크드리스트의 last로 다음은 맨 마지막으로 추가될 것이니까 null 로 설정하여 추가할 노드 생성
// last (last)◁(prev) (생성한노드) (last) ▷ null
last = newNode;
if (l == null)
first = newNode; // last 노드가 null 이라면 아직 한개도 추가된 게 아니니까 first 에 저장
else
l.next = newNode; // last 의 다음(next) 노드에 생성한 노드를 가리키도록 한다.
size++;
}
public void add(int index, E e) {
Node<E> succ = findByIndex(index);
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
}
Node<E> findByIndex(int index) {
// 찾는 인덱스가 총 노드 개수의 절반 이하면 앞에서부터 슨회하여 찾는다.
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 찾는 인덱스가 총 노드 개수의 절반 이상이면 뒤 에서부터 순회하여 찾는다.
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
public E remove(int index) {
Node<E> x = findByIndex(index);
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
return element;
}
public Iterator<E> listIterator(int index) {
return new ListItr();
}
private class ListItr implements Iterator<E> {
private Node<E> lastReturned;
private Node<E> next;
private int nextIndex;
ListItr() {
next = first;
nextIndex = 0;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
}
}
Colored by Color Scripter
|
실전에서는 위처럼 직접 구현할 필요는 없고 언어별로 built-in 된 클래스들을 사용하면 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// Java
List<Integer> l = new LinkedList<>();
l.add(10);
l.add(20);
// C++
stl::list<int> l;
l.push_back(10);
l.push_back(20);
// Python
l = list();
l.append(10)
l.append(20)
print(l[0]);
// kotlin
val l: MutableList<Int> = mutableListOf(); // vs listOf (read only)
l.add(10);
l.add(20);
println(l[0]);
Colored by Color Scripter
|
레퍼런스
- VisuAlgo - Linked List : https://visualgo.net/ko/list
- 생활코딩 : https://opentutorials.org/module/1335/8821
'자료구조(Data Structure)' 카테고리의 다른 글
| 비트셋(BitSet) (0) | 2019.06.18 |
|---|---|
| 배열(Array) (0) | 2019.06.18 |
| 해시테이블(Hash Table) (0) | 2019.06.18 |
| 셋(Set) (0) | 2019.06.18 |
| 덱(Deque) (0) | 2019.06.18 |


